Here’s the transcript of my lecture from the ZijemeIT 2023 conference, enriched with my personal commentary. The original lecture in Czech can be found here. As a little bonus, I’ve included some slides I removed from the deck due to time constraints.
The structure is as follows:
[SLIDE]
The transcribed text.
And optionally, my commentary.
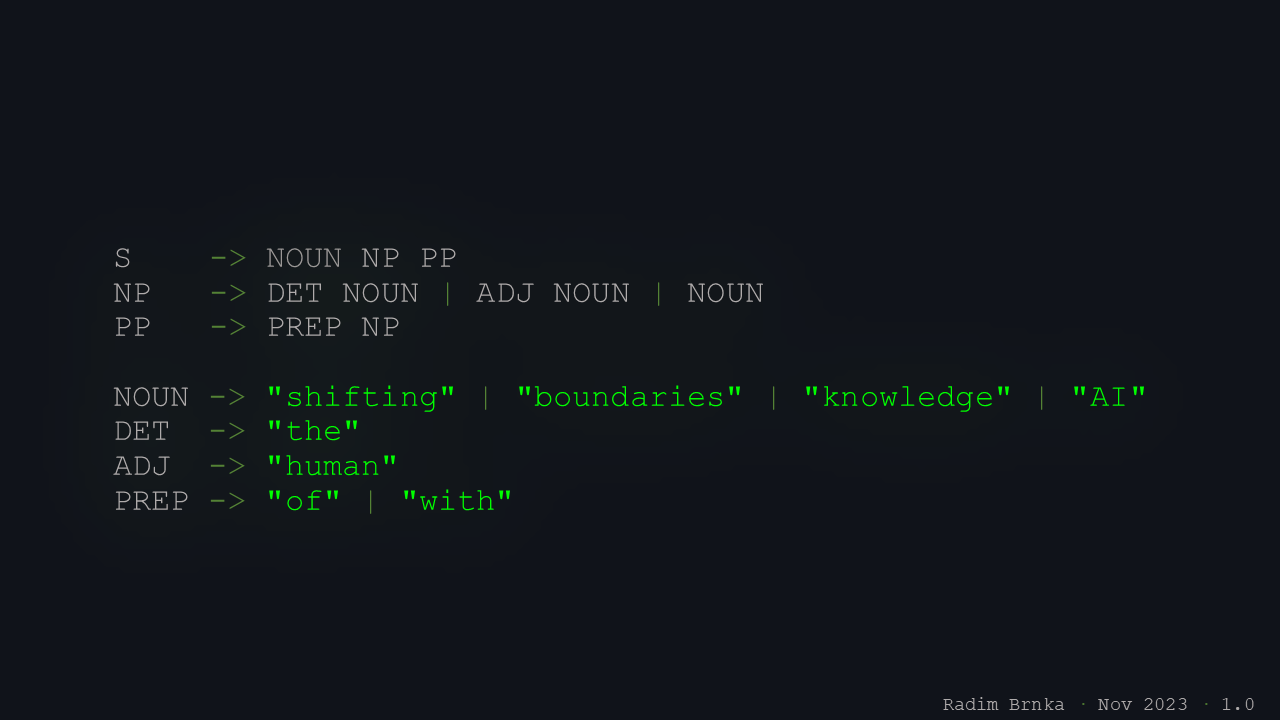
As you’ve probably guessed from the first slide, we’re at the Faculty of Information Technology, so as a small tribute, I framed this slide in the form of a context-free grammar.
The talk will be with a slightly philosophical flavor, which is always a bit dangerous, because the audience can easily tear you apart in the discussion later.
Let’s dive in.
I created this slide with respect to the venue of the lecture, which was the Faculty of Information Technology at Brno University of Technology, my alma mater. Formal languages and automata were among the most inspiring courses of my studies, and displaying the title as a context-free grammar nicely resonates with the lecture’s themes: the importance of unequivocalness and meaning when working with data and machine learning models. This form clearly reduces the ambiguity of the lecture’s title, which is crucial when querying AI systems.
I represented SolarWinds during the conference, and we got a lovely spot for our booth in the hallways of the old monastery, right across from the refreshments, which turned out to be a strategic position to catch hungry bystanders looking for a schnitzel, introduce them the company, and exchange ideas.
With the surge in AI, new perspectives are unfolding in our understanding of the world around us. In the near future, it will become imperative to move beyond age-old paradigms of truth and reality and start rethinking humanity’s problems to harness the power of AI effectively for their solutions. In this session, I aim to navigate you through the fundamentals of what should be our focus and the necessary mental shift required.
The session abstract was provided a couple of months before the session, which always causes you to deliver something a little bit different from what you thought. Sometimes it’s for the better, I believe. This slide wasn’t part of the presentation and was only provided for the conference agenda.
What are we going to discuss today? I don’t really like agenda slides, so I’ll just splash this all at you, burn it into your retinas for a moment, and then we’ll jump right in.
What the audience saw was a brief cognitive shock of the session’s index, displayed for just a couple of seconds but long enough to imprint whatever their brains noticed first.
Truth
I’ll start with a slightly uncomfortable topic: truth. And why talk about truth in the context of artificial intelligence? As humans, when we grow from children to adults, we usually begin with something like “naive realism”: we think that what we experience and see is a direct reflection of objective reality.
To some extent, this model of truth works. But it also has apparent limitations.
At this moment, your brain, still processing the previous slide, instantly suffers a loss of information abundance, preparing you to focus.
If we base truth only on our senses and experience, we easily end up with “truth” that is basically just a consensus. Everyone says it’s true, so it becomes true. We agree with others, and we build truth from what people around us repeat. And of course, everyone brings a piece of themselves into their picture of truth.
In the end, we bake a strange construct: Very noisy, very coloured by bias, and on top of that, binary: either it’s true or it’s not, which suggests that nothing in between can be true, and suddenly the world gets very black-and-white. In science, this kind of truth model doesn’t work. And that’s already built into the scientific method itself; we’re used to looking at truth differently.
You can see I’ve put a tilde before the “objective” word because I treat objective truth as a purely philosophical concept.
So how do we look at truth from a machine’s point of view? We look at data. Today, truth is statistical primarily. We use statistical methods, but from the perspective of computing and AI, truth is agnostic. Humans can only influence it through the data they produce. If the data are biased, then the “truth” we infer from them is implicitly biased as well. If the data are cleaner, the model of truth becomes cleaner.
What we’re left with is some probabilistic model of truth, and that’s what we actually work with in science and informatics.
So it’s not black-and-white. It’s more of a gradient.
The title is displayed at the same position as on the previous slide to maintain topic fluency. This form of extra dimensionality carries through the entire session wherever possible, it’s also establishing the protocol of how the information in the slides will be presented and what’s the “on slide/spoken” ratio.
The “Truth” is purposely presented within green “walls” that squeeze it between these two paradigms. The image in the background represents a half-man, half-machine according to what level of truth is closer to each of them. The tilde in the “~Objective” says that I don’t believe in an entirely objective truth available to us.
An interesting point on the truth I mention is that "Humans can only influence it through the data they produce.” Of course, especially with GenAI models, we can add multiple layers to “improve” and align the output as needed. My initial thought here was based solely on pure inference.
I’m currently working on a whole article about the topic of truth and will share the link once it’s finished.
Knowledge
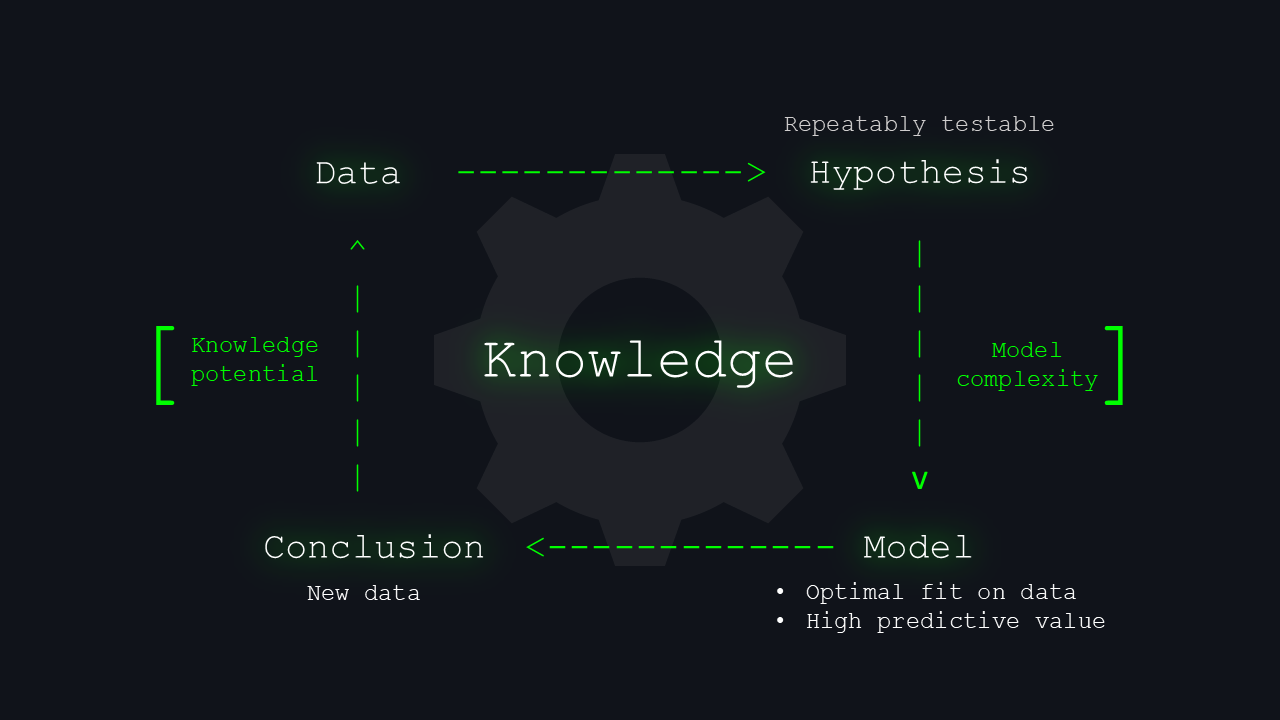
And because this talk is about knowledge, not just truth, the question is: how do we get from this probabilistic model of truth back to a model of knowledge? We must reduce everything into models so that we can even discuss it.
If we start at the level of raw data, we humans receive sensory inputs from the world around us. From that data, we begin to form hypotheses. A hypothesis is nice, but if you can’t test it, it’s almost useless, and nobody will really care. So it’s important to test hypotheses with models.
We’re looking for models that fit the data well and, ideally, have predictive power because both our thinking and our brains are fundamentally predictive. If we had to process everything by brute force — like who is sitting where or standing where — it would be impossible; instead, we constantly predict what will be there, then check whether reality matches our prediction.
We build models in science in exactly the same way. From them, we draw conclusions, and these conclusions can be treated as a certain level of probabilistic truth: truth that holds under specific conditions, in a specific context, with some probability. If you imagine this process as a spiral or an endless cycle of learning, we keep feeding new data back into the cycle and continuously deepen what we know about the world. This whole model has two overlapping boundaries. One is our overall potential for knowledge. The second is the complexity of the models we use to test hypotheses, and therefore the limits of what humans can understand
How do we pursue knowledge when faced with this version of truth? We infer it from data by formulating testable hypotheses and creating models with strong predictive capabilities. The conclusions drawn nudge us closer to the truth and become new data, fueling a relentless cycle driven by our desire for discovery with boundaries only determined by the extent of our potential for knowledge — a frontier that can be shifted..
But what are its limits? I elaborate more on this topic in on of my other lectures:
Let me switch to another little model. An image is worth a thousand words.
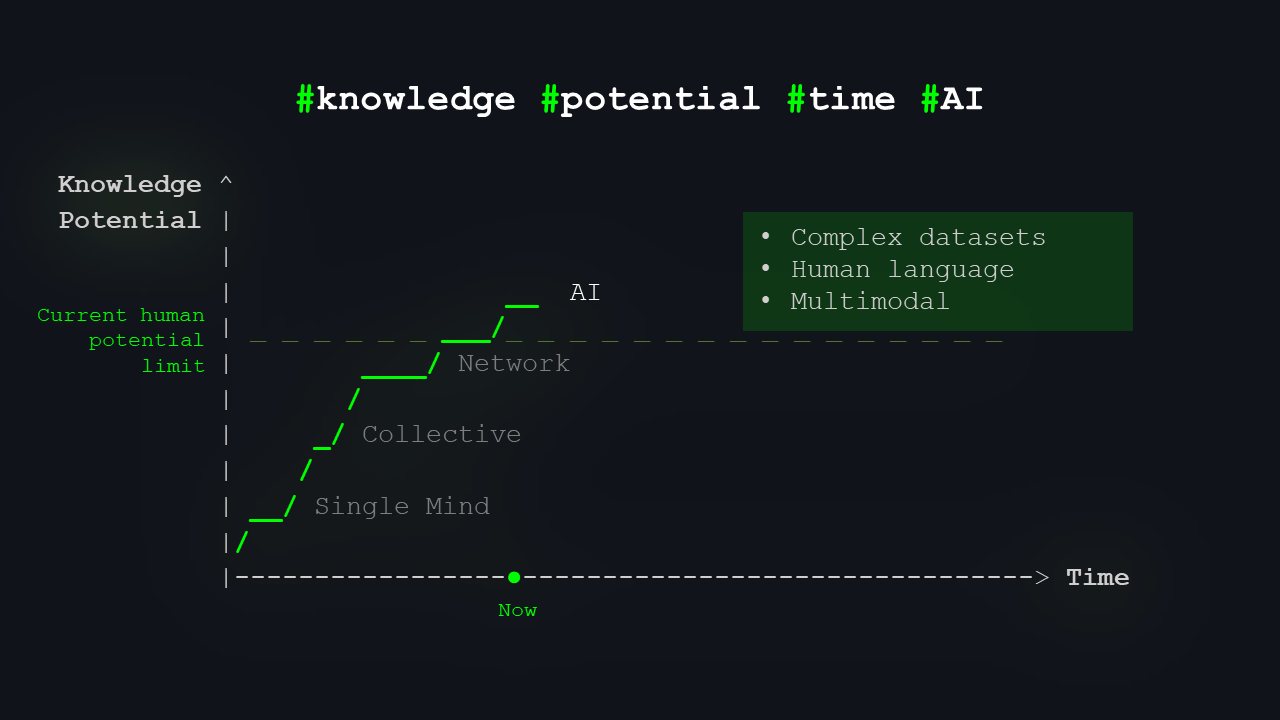
On the y-axis, we have “potential for knowledge”, and on the x-axis, we have time. You can probably guess there will be a trending curve, showing how our brains, our collective thinking, and technology have evolved over time. Roughly, at least – reality is always messier.
I’ll mark a few milestones.
The first milestone is the knowledge potential of a single individual. There was probably a time in human history when the entire body of “useful knowledge” could fit into one person’s head. I think it was Komenský who used the term “pansophy”, the universal wisdom, meaning a person could grasp almost everything that could be known and used in life.
That moment is definitely gone. Even if it ever existed, it was very brief.
It began with a single human mind, which once could have contained all available knowledge. However, as our understanding of the world advanced faster than our brains could grow, knowledge outpaced our mental capacity. The term “pansophy”—meaning “universal wisdom”—originates from the 17th century, when it was believed one mind could hold all the knowledge of that era.
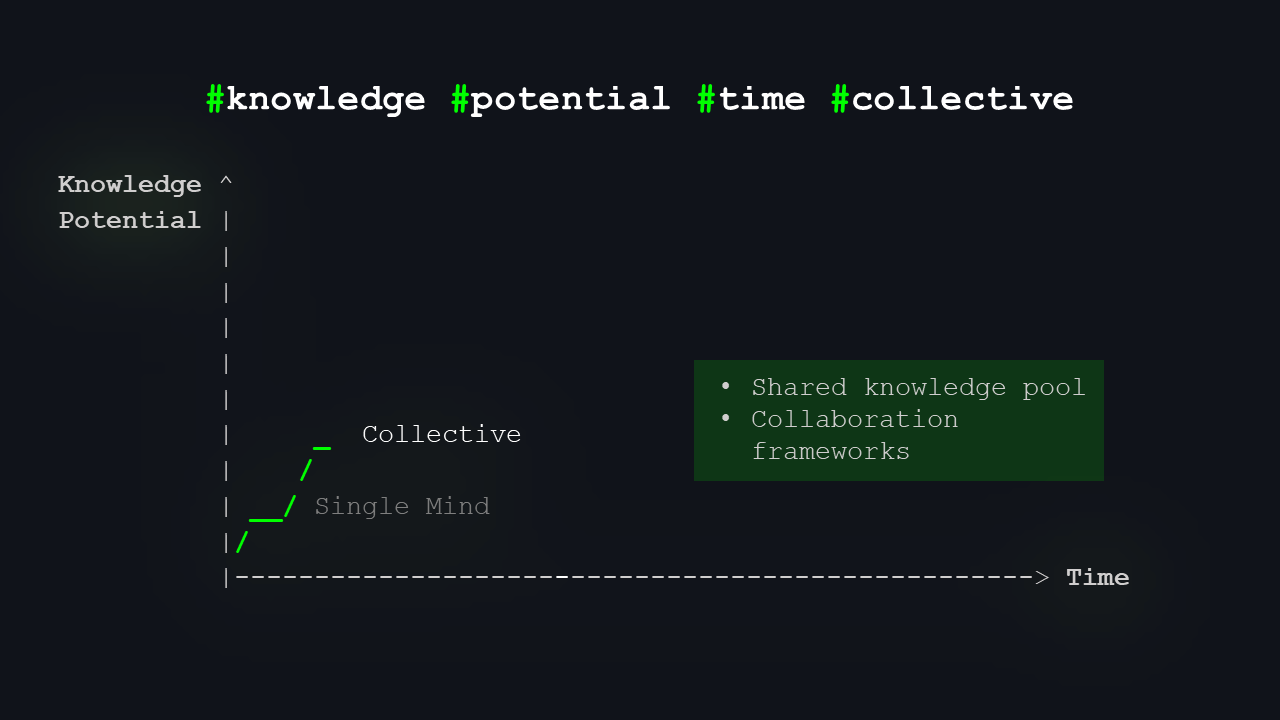
Then we learned to work in collectives. At first, small groups, tribes, and teams, but as soon as we started collaborating, sharing, and mixing knowledge and experience, our potential shot up. Everyone could know a little bit, and together we could cover a lot more.
Over time, we started sharing knowledge and expanding it collectively. We collaborated to reach wisdom surpassing individual capabilities. We created various groups—packs, guilds, teams, communities, societies—and together, we learned to hunt mammoths, construct bridges, and carry out complex surgeries such as triple heart bypasses.
The third level we’re roughly at now is the network. Under “network,” you can naturally think of the internet, but also of any large group of people who can exchange vast amounts of data, information, and knowledge in real time and work with it and develop it. That’s the “network stage” – today’s internet, our data reality, our information reality.
This stage faces a major issue: too many inputs, too many actors, and too much noise. It’s becoming very difficult to distinguish between real, reliable knowledge and nonsense.
And of course, how else do we fix a technological problem but with more technology?
Ultimately, we’ve built the most complex structures yet: networks. Many entities, spread across great distances, can now access and share knowledge almost instantly. This knowledge is constantly exchanged, developed, and utilized. However, we’re starting to feel overwhelmed by the huge volume of data. Telling valid models from false ones is becoming more challenging.
This highlights our current situation and explains why I see AI as the essential next step in understanding the vast data landscape.
So here is the breaking point we’re approaching – where artificial intelligence comes into play. Especially this year, it’s a huge hype.
I come from the “old AI” days, when AI wasn’t so sexy – over ten years ago. Today, everyone mostly talks about generative models and large language models. I’m a bit old-school, so I won’t go deep into history; otherwise, we’d be here for more than twenty minutes.
What does AI offer us today? It can work with complex, multimodal data. You can feed it video, talk to it in natural language, give it images, give it all kinds of instructions, and it will talk back to you. That’s roughly where we are now.
AI systems trained on all the data we have, capable of processing complex and multimodal queries and interacting with us in our own language, represent the next frontier. This is likely the point at which we surpass the limits of human potential alone.
But the question remains: how much further can it take us?
I started with machine learning in 2008 by winning an AI tic-tac-toe tournament that was part of our “Fundamentals of Artificial Intelligence” course during my studies. It wasn’t true AI, just smart heuristics, but it was so fast that it actually beat other models thanks to a scoring system that awarded points for both results and speed. It had a complexity of O(SIZE²), no recursion, and no minimax, making it very fast. Because of the missing minimax implementation, I did not receive the top rating despite winning. I focused on optimizing for speed rather than calculating the best move for a long time. But it was enough to spark excitement for machine learning beyond the Terminator movies.
Later, I wrote my master’s thesis on an optimization of neural networks and their combination with chaos theory in stock market prediction. That was well before the genAI bubble.
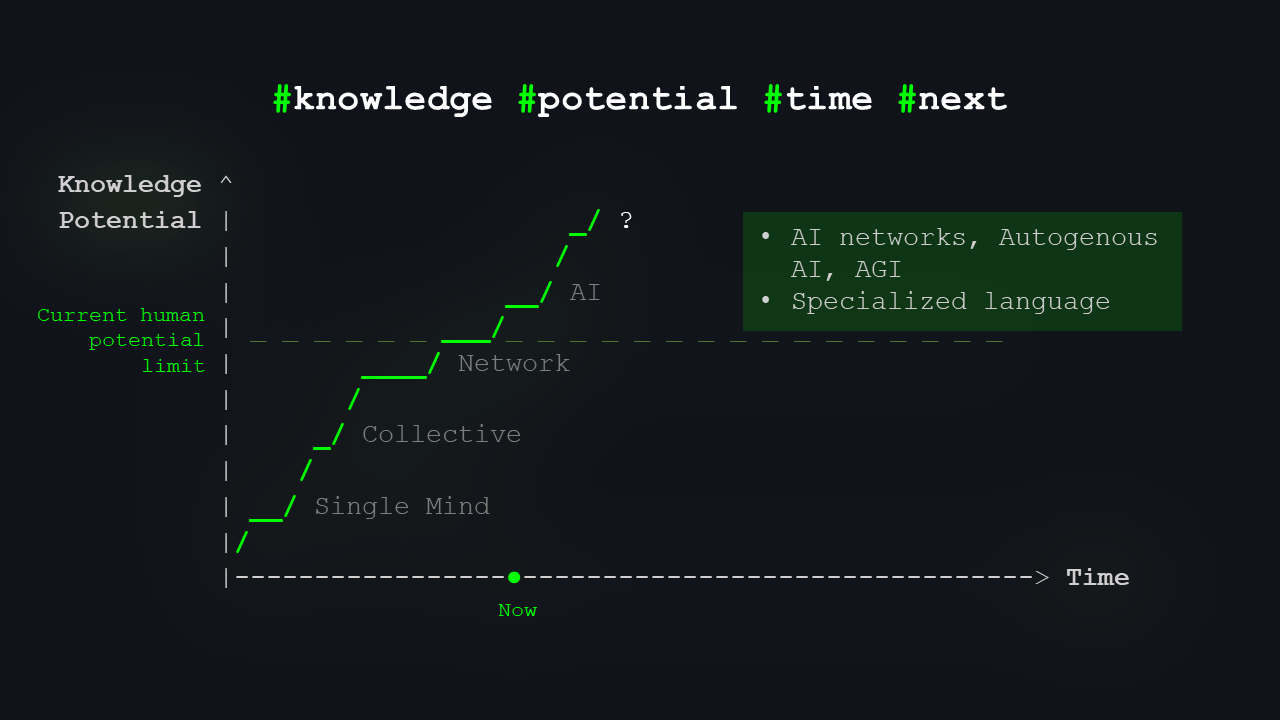
Where we can go from here is probably more of a topic for an offline beer after the talk. You’ve surely heard terms like AGI, artificial general intelligence, or self-improving AI — systems capable of creating their own enhanced versions and offspring. These systems could become so advanced that they might not communicate with us in our language without a “translation layer” from their internal language, which might be more aligned with the structure of reality itself.
Predicting the future is difficult, but terms like AGI, the singularity, and autogenous AIs are often discussed. I believe these systems will need to go beyond human language limits and redefine many current concepts to better model reality than humans ever could.
Let me make a short detour. I’m a big fan of humans. I think people still have a lot to offer and should try to keep up with AI.
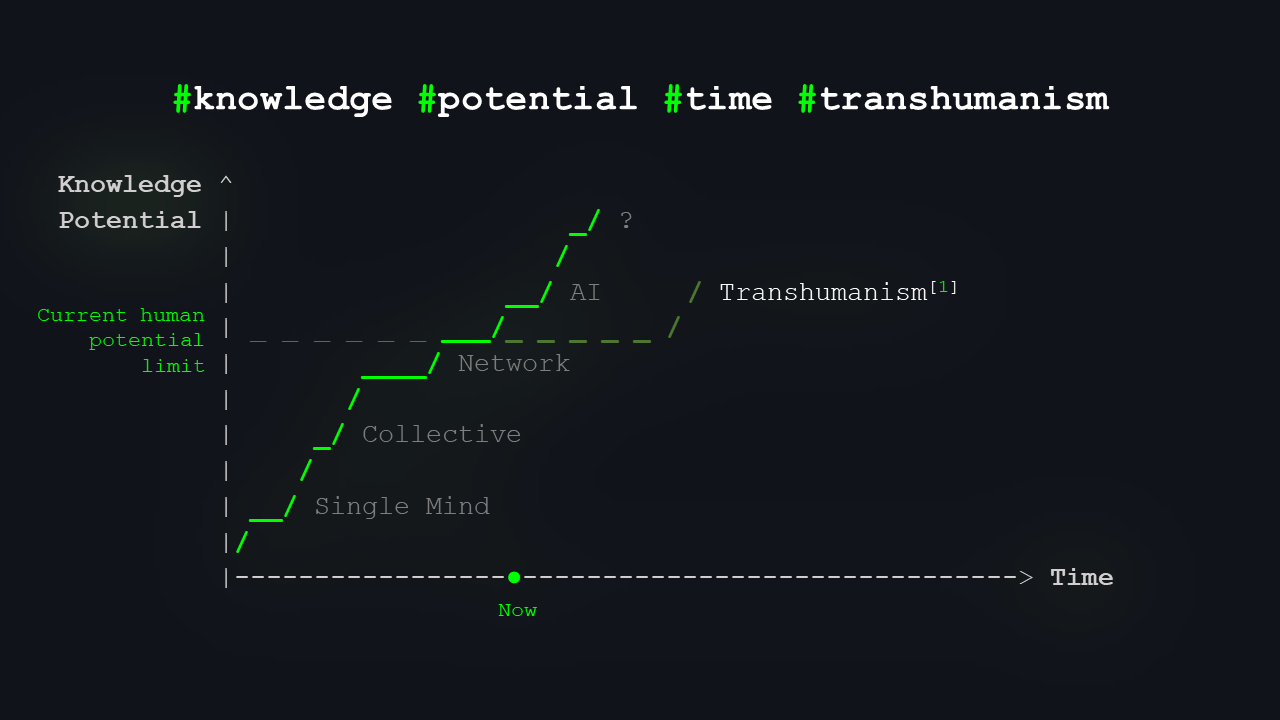
You might have heard the term “transhumanism1”: the idea of extending or enhancing our cognitive abilities. That can include anything from genetic engineering and biohacking to projects like Neuralink from Elon Musk. It’s about anything that could push our potential a little closer to that “upper” curve in the future.
The curve of today’s human potential is not straight; it’s a staircase.
In our model, I’ve represented human potential as a constant for simplicity’s sake. Clearly, it’s not; it has been increasing over time. Yet, the pressing question is whether humanity can keep up with AI’s pace. Is it feasible for human and AI capabilities to converge once more? Could we modify or evolve ourselves to extend our own limits? We have avenues to explore. I am certain there is a path forward. But for what cost?
The big question is: what kind of knowledge can we reach with the help of AI?
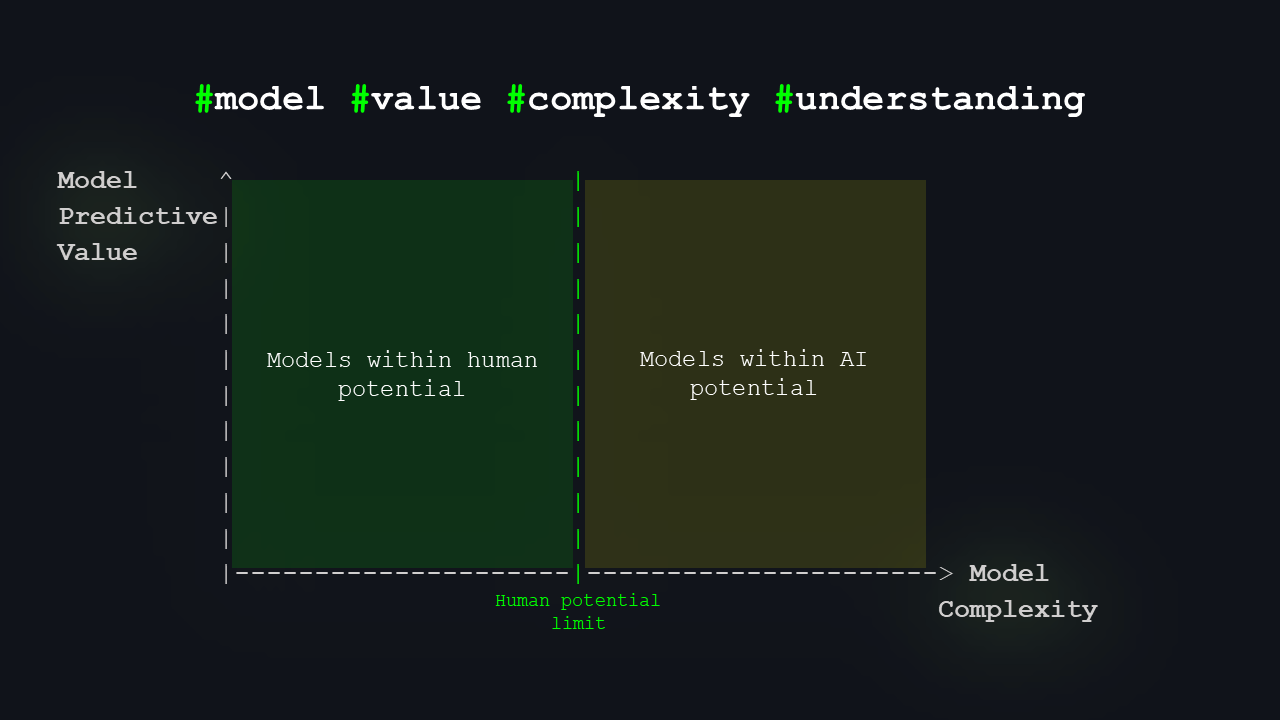
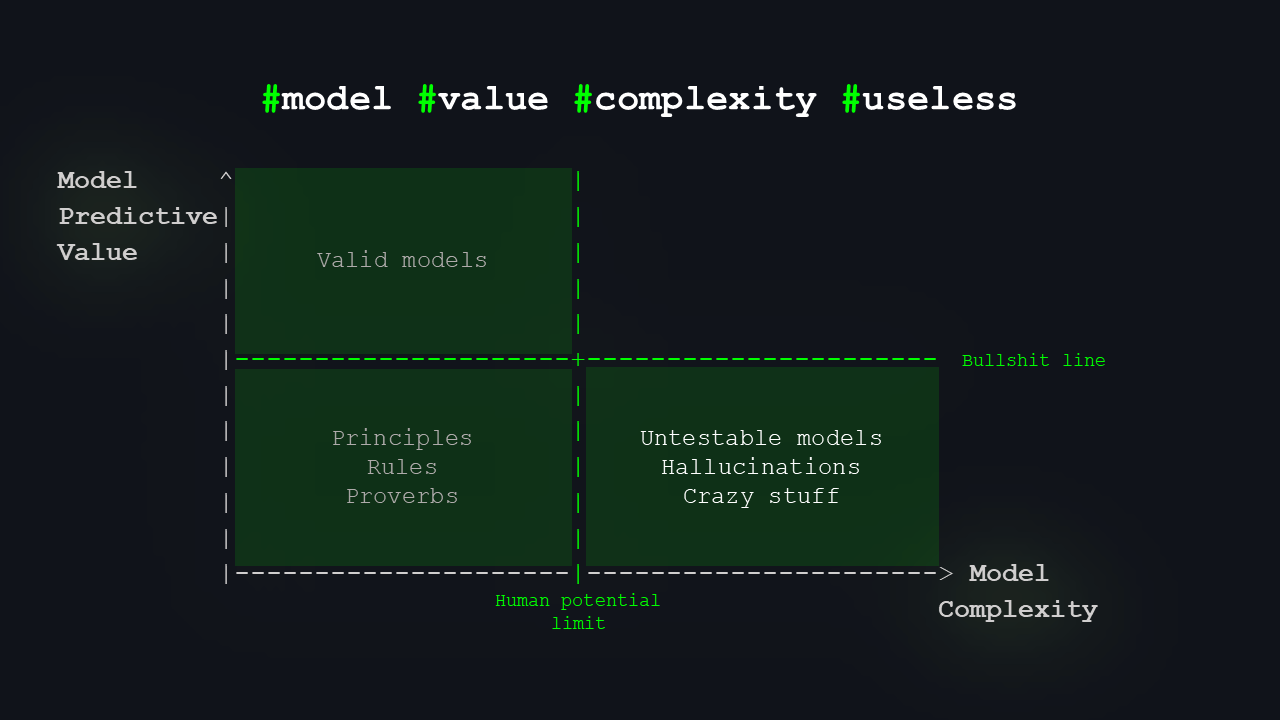
This time, we’ll model “predictive value” or “usefulness” on the vertical axis, and model complexity on the horizontal axis. We’ll split the graph a bit. Here’s the limit of human potential. That nicely divides the space into two areas: on the left, models humans can understand; on the right, models we probably cannot, but where AI could push us a bit further.
On the left will be most of what we already know, the theories we can actually reason about.
On the right, there’s a space that signifies the window of opportunity for AI.
Our minds and networks are limited in the complexity of models they can understand. We interpret the world through models we developed and comprehend, such as meteorology or quantum mechanics. There is a core body of knowledge within human capacity. Yet, there exists another realm of models that can offer useful predictions but are beyond our ability to understand their internal mechanisms.
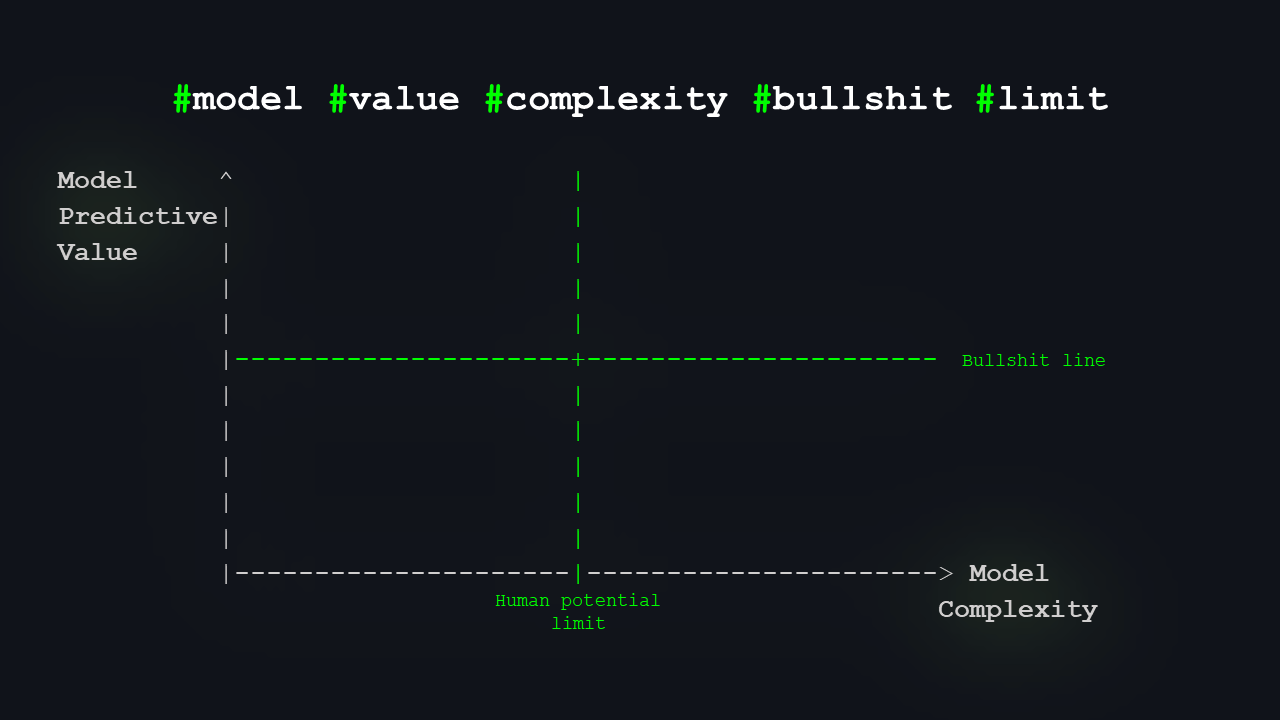
I’ll add one more boundary: what I call the “bullshit line”. Anything below this line has insufficient predictive value to warrant scientific or technical interest.
The “bullshit line” marks the threshold of a model’s value and essentially separates what can be considered a valid scientific theory or a useful model from what cannot. Anything below this line is, frankly, unreliable. 🙂
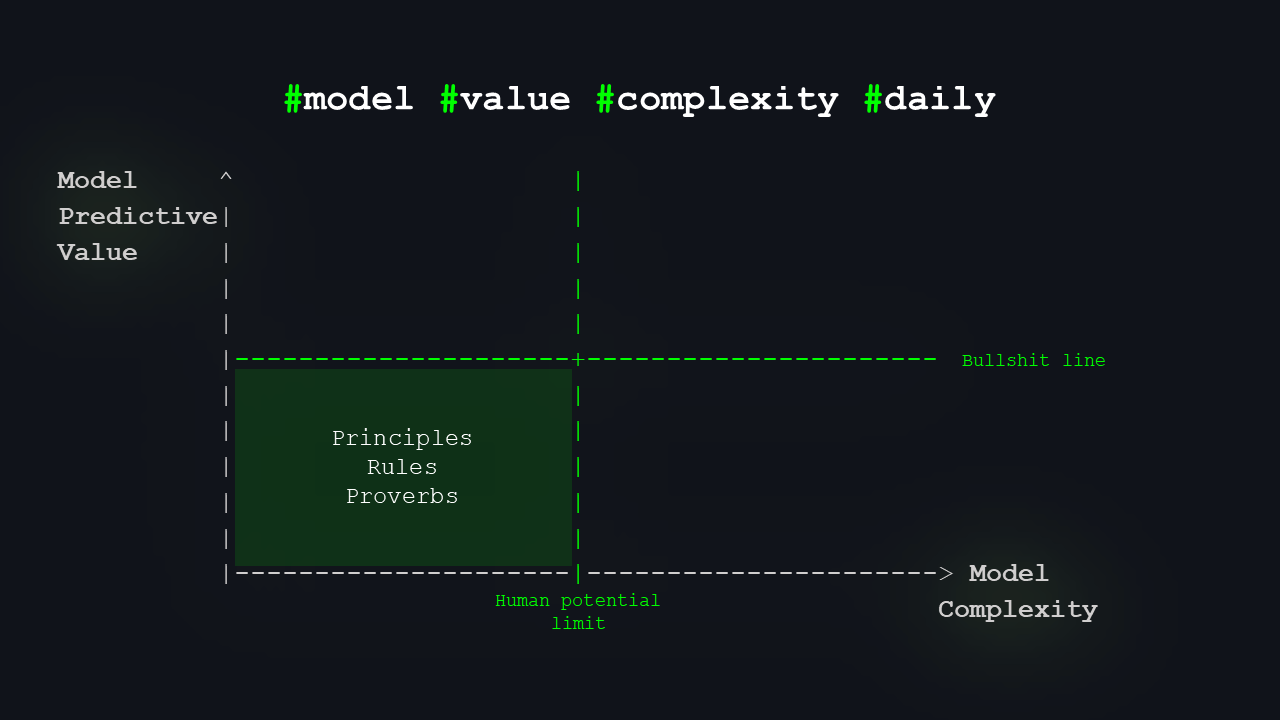
Now, what lives where? Down here on the left, we have folk wisdom, proverbs, rules of thumb – simple models that are good enough for everyday life.
If you miss a train because you imagined it leaving later based on some simple model, it’s annoying but not disastrous.
We don’t need AI there.
There are now four quadrants. The bottom left quadrant contains models that are sufficient for everyday life or to get thousands of followers 🙂
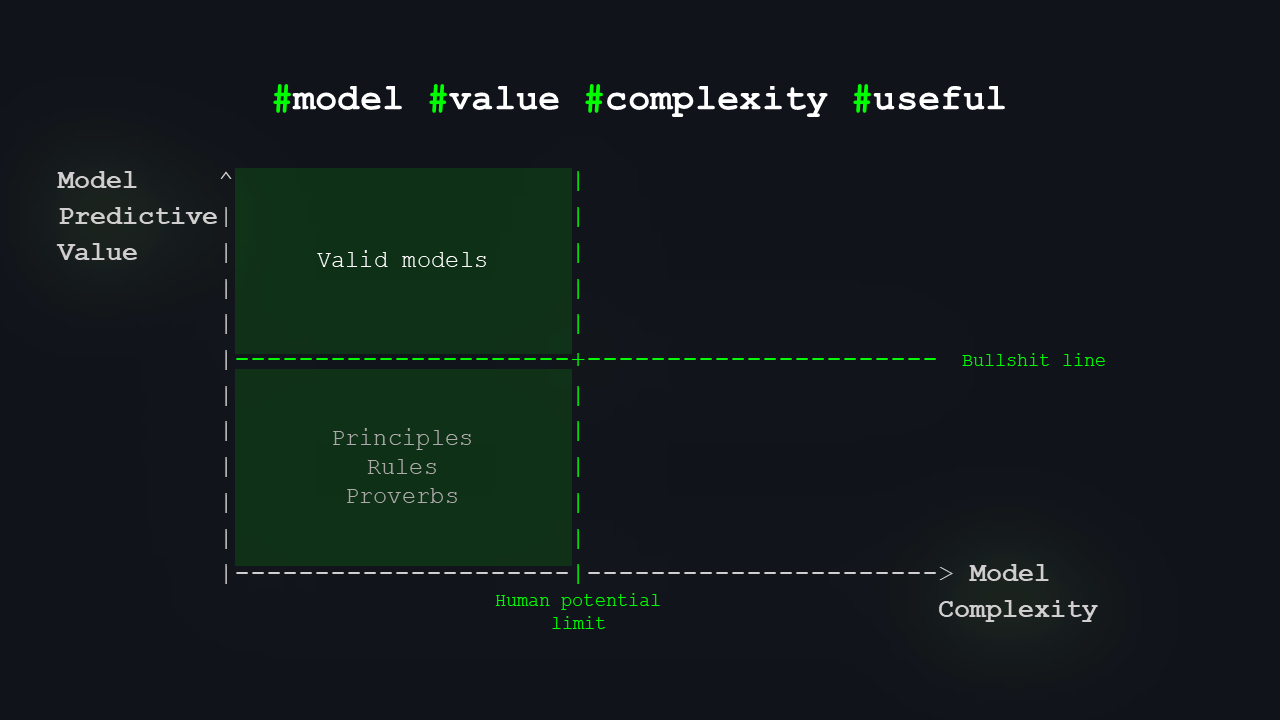
Up here, we have models that are valid and useful: the most rigorous scientific theories and the highest-quality knowledge.
In the upper left quadrant, we find models that are validated, thoroughly tested, and used with a high success rate, yet remain within the complexity our most brilliant minds can handle.
On the bottom right, we have the real bullshit: models that can’t be tested, pure hallucinations, ideas people make up on drugs, totally vague, impossible to formulate, impossible to verify, and therefore useless for prediction.
The bottom right quadrant is designated for untestable models and ideas that appear plausible but cannot be formalized or are simply too wild.
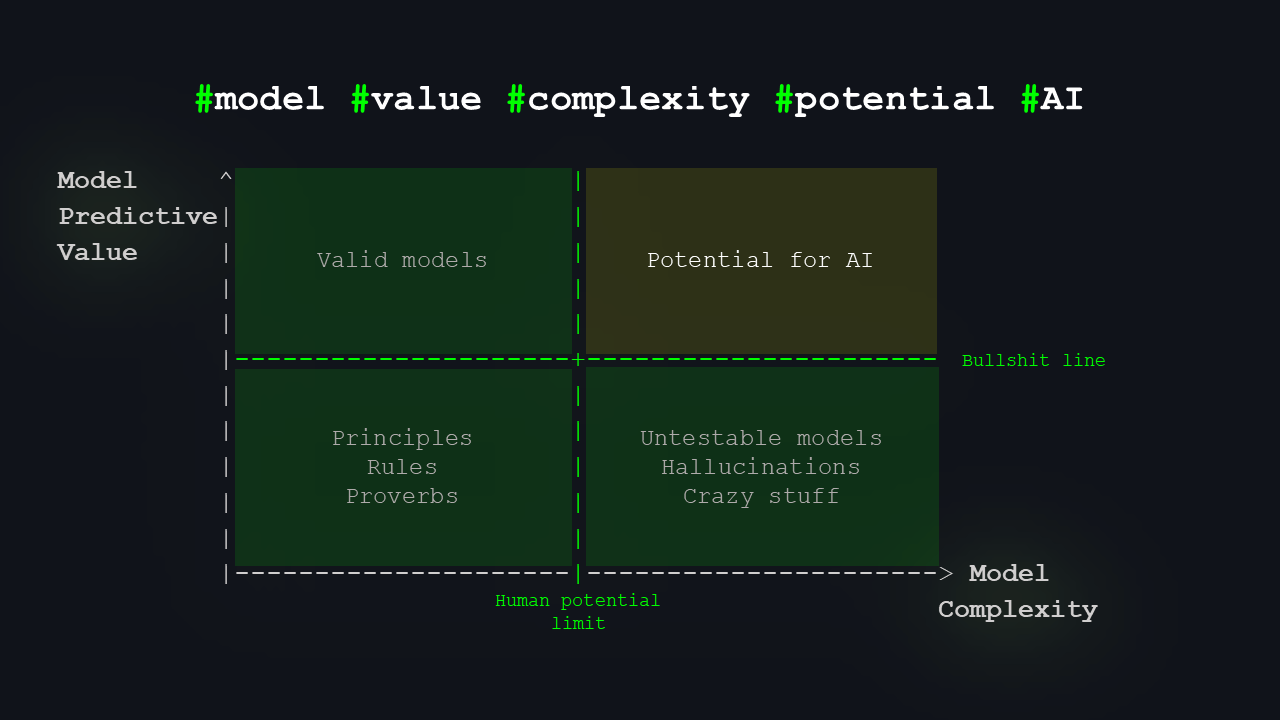
So what’s left is a kind of “golden quadrant”: models that surpass human limits but have high predictive value. That’s where I’d place the biggest potential for AI to expand our knowledge.
The upper right quadrant is our ‘golden quadrant.’ It holds the potential for models that are both highly complex—beyond human understanding—and extremely useful. As mentioned earlier, the human potential line isn’t fixed, and there are models within our potential that we haven't yet discovered. AI can play a key role in uncovering these as well.
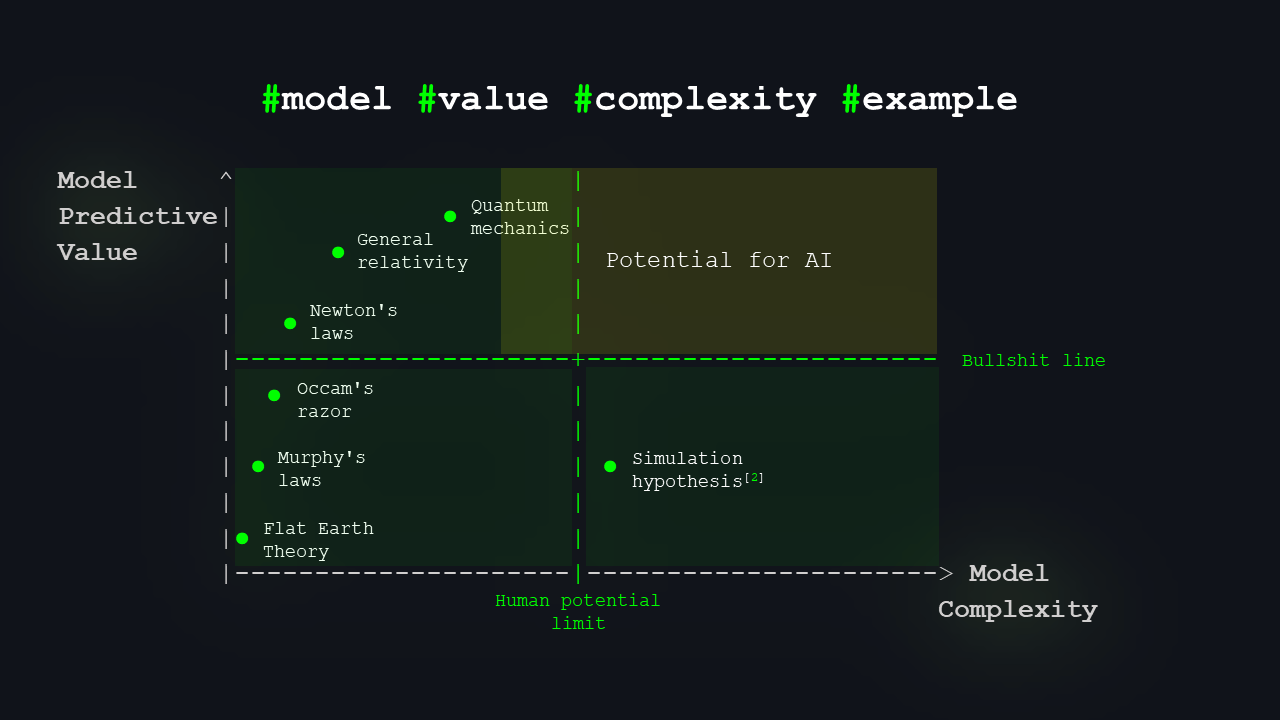
I want to give a few examples for the first three quadrants. Treading carefully to avoid offense, in the bottom-right quadrant, I’ve included a single example: the simulation hypothesis2, which is reasonably complex but remains untestable so far. Even if proven, it’s unlikely to provide predictive value beyond Murphy’s Laws, like “If we’re living in a simulation, it’s bound to crash at the worst possible time.”
As shown, the lower left contains flat Earth theory and similar nonsense, while the upper areas approach the human limit, with fields like quantum mechanics and advanced physics. You likely noticed I extended the golden quadrant into this region because we haven’t fully explored the upper left area yet. There’s still a wealth of knowledge to discover, even with AI assisting us in analyzing vast datasets and searching for patterns and structures beyond human perception.
The leading theory of particle physics is the Standard Model. It describes all fundamental physical interactions except for gravity.
Yet, the 2023 Muon g-2 experiment confirmed a 5.1σ deviation from its prediction, with a data fit of about 10⁻⁶. This suggests that our current model is significantly inaccurate, leaving ample room for further exploration.
The Golden Quadrant of AI’s Potential
So, what kinds of things belong in that golden quadrant?
Most of you know common AI use cases, so I’ll just mention a few. For example, detecting “dirty data3”: highly noisy, corrupted, fake, or fabricated data. That’s something we’ll see more and more of on the internet. Data that is too noisy or has no real underlying foundation, errors, or made-up data. Still data – but much less valuable.
Then there’s what we call “dark data4”: data we gather but never examine, as we don’t see immediate value in it. However, there could be hidden insights there – AI can help explore this area.
In many areas of physics, we seek to unify concepts and interactions, reducing the number of independent ideas. AI could assist by discovering patterns and connections we don’t see. It can help find new combinations and meanings. We describe reality using our human categories, but that doesn’t mean AI will necessarily use the same ones. If AI looks at a table full of bottles, it might see something completely different and label it in a way we would never think of. It can detect symmetries and similarities we’re blind to. That’s a major benefit: AI is not anthropocentric. It doesn’t have to view the world through a human lens. Of course, when we force it into a language model, it becomes very human-centric again. But there are other types of foundation models, not just language-based ones.
Another area is causal inference: we often observe only correlation, but in some cases, AI might help us identify causal relationships. Those are the more practical applications.
If we ventured into the “spiritual” realm, we might ask questions like: what is life, what is consciousness, what is infinity, what is reality, how gravity actually works, or whether free will exists. I don’t dare say that AI will soon help us answer these—still science fiction—but there are already thinkers who try to connect hard science with these traditionally philosophical questions.
There are authors who write about this, and we’re starting to see hypotheses that are at least in principle testable. I think the next few years will be extremely exciting in this area. Assuming, of course, there’s no Skynet moment and it all doesn’t end just as it begins.
Let’s hope not.
Near the edge of human potential, there’s a wealth of knowledge within reach that may be obscured by noise or overlooked because we haven’t yet directed our attention there. AI can help us by sifting through noisy data, extracting value from unprocessed data, and tying up loose ends in our thoughts and hypotheses.
It can integrate concepts, discover combinations we’ve never considered, coin new terms, spot patterns we’ve missed, identify symmetries in data to pinpoint similarities in their origins, and discern causality where we’ve only seen correlation.
If we aim to explore further, many themes and concepts lie outside our current scientific understanding, and our minds may not even grasp them.
So where are we now in terms of our potential, and where does AI sit in that picture?
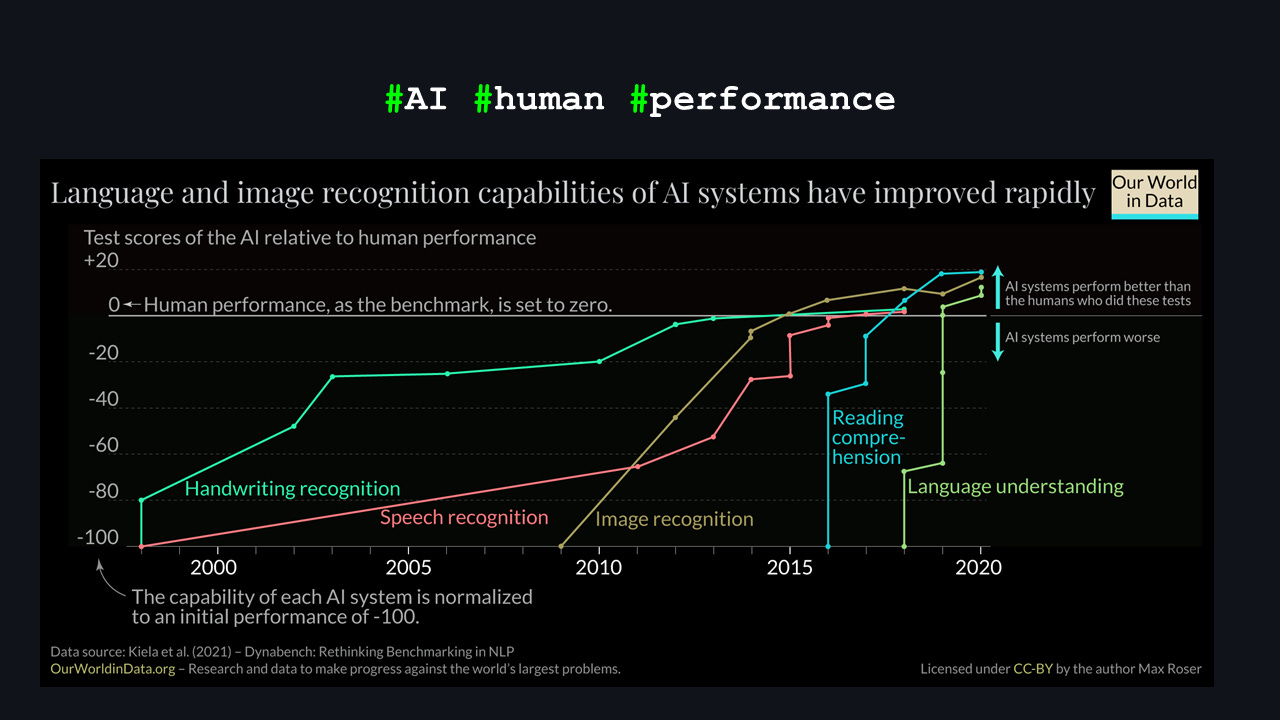
I borrowed this nice graph from Max Roser, because I really didn’t want to redraw it in ASCII. You can see various human activities that we typically perform quite well, and how AI is catching up or even surpassing us in them.
At first glance, that looks a bit scary, but it also means we’re entering that golden quadrant: AI can now understand written text better than most of us. That’s genuinely scary.
I myself read some books two or three times before I really get them.
How close is AI to helping us with the challenges of the golden quadrant? I’ve adapted this chart from Max Roser in 2023, showing how AI systems have improved over time compared to a human baseline. It demonstrates that recently, AI has started to outperform humans in many areas, so the golden quadrant is not just on the horizon but already here.
Challenges and Paradigm Shift
Let me end with a few challenges we face ahead. Most of them are at the data level.
First: quality. We’ll have more and more dirty data, fake data. How do you build a reliable predictive model if you don’t know what in your dataset is fundamentally correct?
Second: Do we even have enough data? We collect petabytes and exabytes, but is that really enough to understand the universe?
Third: Real-time data. Many models are trained for years; they’re huge and complex, and it’s hard to keep them up to date with fresh data in real time. Often, they sit there and do inference on new inputs, like today’s large language models. We’re not yet good at continuously retraining them to keep up with the latest reality.
Then there’s anthropocentric semantics –I mentioned that already.
Next, we have a lot of “soft data”: if you listen to how Gen Z talks today, which is probably most of you, older people often don’t understand you at all. So why should a machine understand you easily? We use a lot of slang and changing expressions, which is hard for models to keep up with.
The challenges revolve around working with data captured in semantics, which allows us to understand it. Our understanding of data is not needed for AI models, but the data challenges still apply:
Real-time data presents a significant hurdle, as AI models require extensive time and resources to train, preventing direct real-time processing.
Soft data, language-specific nuances like narratives and memes, which we sometimes comprehend.
Noise, dirty data, and false data further complicate matters.
A key question is whether we have enough data to drive significant progress, and if so, whether we have appropriate computational power to process it.
Emergent data: New information or patterns that arise at certain levels of complexity must be incorporated.
AI models face inherent challenges:
Trust in Inductive Reasoning: Can we rely on models if we only have inductive evidence of their validity, knowing they could fail?
The need for foundational models: We must examine the data on which models are trained and understand their structure. Relying solely on large language models may be insufficient.
And finally: language. I skipped a whole chapter on language, but language is crucial for how we frame problems, communicate them, and share knowledge. We’ll have to learn to ask the right questions and correctly decode the answers. We want answers that are testable – and ideally ones that don’t accidentally blow up a nuclear reactor somewhere.
And that’s it from me. I hope I finished exactly on time.
Thank you.
I skipped the part about the language so I could finish exactly at the 20-minute mark, but at least you get the chance to read it at the end.
Discussion
The last slide I presented was meant to engage the audience and encourage further discussion after the session. Another 15 minutes of questions from the audience followed. Sharing it next. I selected a few questions related to the lecture itself:
Audience: One philosophical question — you touched on transhumanism. Some people connect it with collective consciousness. Isn’t that dangerous?
I see it mainly as an interesting area — we’ll likely have neural implants, augmented cognition… but there are substantial security concerns. With quantum computing coming… …our current cryptographic systems might be broken overnight. So isn’t the risk enormous?
Me: I’ll approach this from two perspectives.
First, I completely agree — connecting humans directly to machines poses significant risks. Bad guys are always one step ahead. You could literally have someone walking around whose thoughts are manipulated externally, and there would be no easy way to detect it.
Regarding cryptography, quantum-resistant crypto is already being developed. We’ll just need a new wave of mathematics and protocols. Honestly, I’m not too worried about this part.
People have always experimented with self-enhancement — mentally and physically. Bryan Johnson takes hundreds of supplements daily, trying to slow aging or improve cognition. Others wear devices that continuously track emotions or measure biometrics, like the first-world cyborg Neil Harbisson. So, this isn’t a new trend. But the more fascinating direction is neuroscience — not enhancing the brain, but understanding it. The brain constructs reality and seems to be a creation to observe and understand. If we know the process of understanding, we might understand reality itself more deeply. That’s why psychedelic-assisted therapy is gaining renewed interest.
Studying how chemicals alter perception allows us to reverse-engineer cognitive patterns. There’s a lot of research happening in this area right now. At the National Institute of Mental Health in the Czech Republic, volunteers line up to participate in live studies, receive psychedelics in a controlled environment, and contribute to ongoing research.
Audience: You mentioned combining science with existential questions— life and consciousness. Have you come across work that does this well?
Me: Yes — I recommend Curt Jaimungal’s podcast “Theories of Everything”. He interviews highly educated guests who present their unique, fascinating models of reality, consciousness, physics, and metaphysics—all thoroughly discussed. If I had to choose one episode, it would be the first one with Bernardo Kastrup, a holder of PhDs in computer science and psychology, who explains his worldview in a very clear, ego-detached way.
Audience: You mentioned humans have limits. We do. Does AI have limits?
Me: That’s an excellent question. We don’t know. I skipped a definition of AI in the context of this lecture, but I believe AI can extend our potential and cognitive boundaries, though it may not be the final stage of intelligence.
Everything here is speculative — why would a human-made technology be the end of evolution? The universe is billions of years old; there is plenty of time left, likely for other forms of intelligence to emerge.
I don’t think AI is the final chapter. I also don’t think we’ll be around to see the end.
And there’s more. If you’ve read this far and you’re interested in the additional content, you can find it here: